

"Somewhere between delightful and unnerving"
Claude Fable, OpenAI olive branch, rebutting AI denialism, and more



Dispatch from Mitch
Anthropic publicly releases Fable, a Mythos-class model
I think it’s really important that people understand what today’s AIs can already do. Too many dismissals of the extinction threat come down to assumptions that we’re a long way off from AIs that could outmaneuver humanity. And too many of these assumptions stem from an underwhelming experience with a basic chatbot, perhaps from 2024 — practically the stone age compared to the agentic frontier in 2026.
It’s not a joke that many of us trying to do something about the extinction problem think one of the most effective ways to light a fire under policymakers is to give them hands-on demonstrations of agents at work.
So you can be better briefed than most people in government simply by trying these models out for yourself. Failing that, try reading the first-person accounts of people experienced in putting models through their paces. Better still: Do both.
All of this is to say that Anthropic released a consumer version of its Claude Mythos model today. It’s called Fable. You can try it yourself, with a paid plan. And you should strongly consider reading Ethan Mollick’s new Mythos test drive report, even if you’re going to do your own tests — otherwise, you might set your sights too low.
Mythos, remember, is the model Anthropic held back from wide release due to its potentially destabilizing hacking abilities. This cyber prowess emerged despite Mythos being a general-purpose model not specialized in cybersecurity. So it’s not just hacking that Mythos is substantially better at. It’s believed to be a bigger model, trained on substantially more compute than perhaps anything else out there. It is correspondingly more capable at most tasks, and correspondingly more expensive to run. This is the frontier.
Fable is what Mythos looks like after Anthropic has installed what it thinks are adequate guardrails against abuse, especially in the realms of cybersecurity, biosecurity, and frontier AI development — yes, the company is very concerned that others would use Mythos to create capable rivals.
Mollick describes using the new model as “somewhere between delightful and unnerving,” because he could just ask for things, and they would happen. He gave simple, vague prompts for complex projects and the AI handled the rest: specifying details, spinning up subagents as appropriate, checking work against targets, and iterating repeatedly for up to twelve hours. Mollick’s follow-up requests were minimal.
One of Mollick’s prompts asked for a 10-page epic rhyming poem “about a haircut” where every word starts with the letter s. I’m rather shocked at the fluidity, coherence, and sophistication of the finished product.
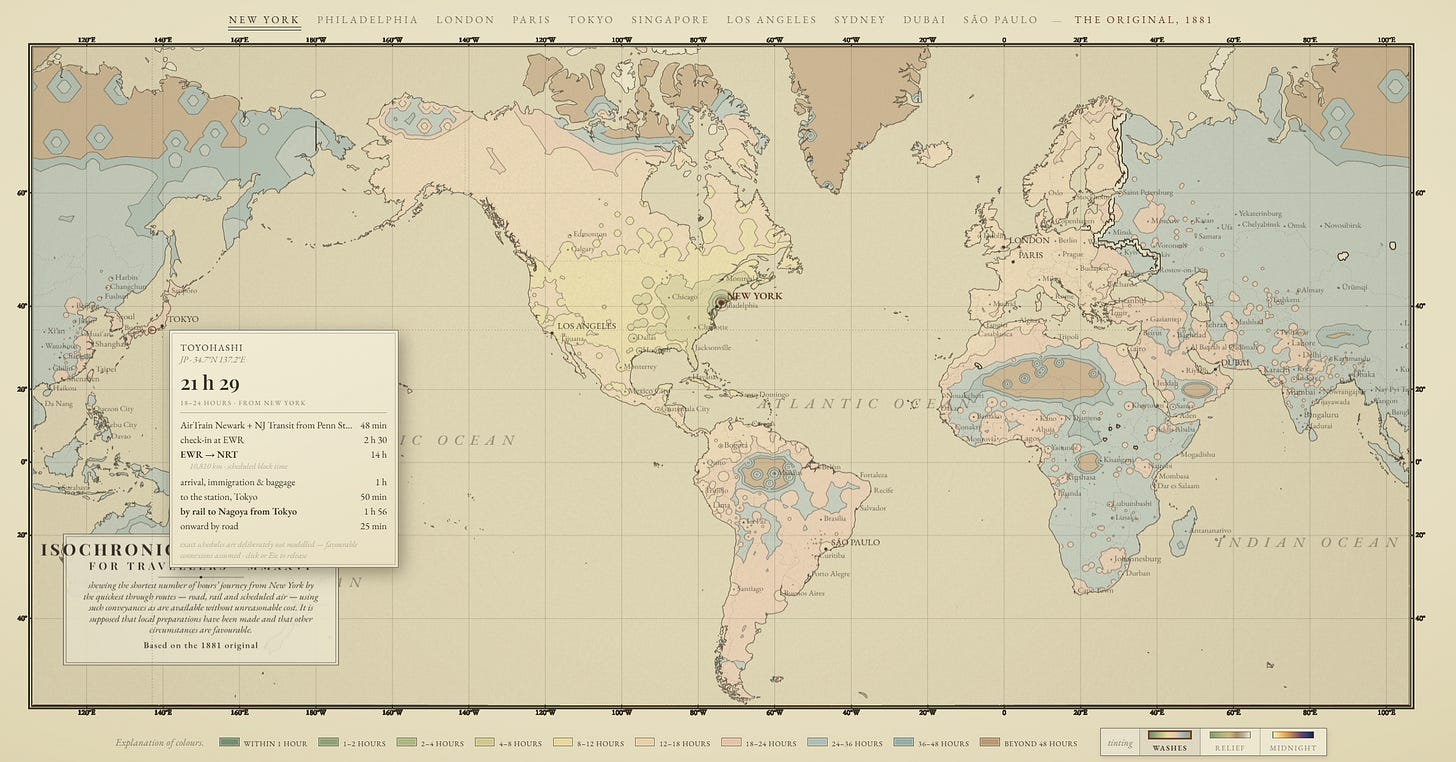
I’m also quite impressed by the interactive isochrone map — a type of map that tells you how long it would take to travel to the destinations on it. This one is in the style of an 1881 map that showed travel times from London. Mythos’s version lets you pick one of several starting cities, and shows you the rough itinerary to achieve the travel time shown to reach the location at your cursor. Completing this map required Mythos to oversee research on thousands of real-world routes.
The Fable release coincides with a minor bump to the more permissive Mythos model itself, from “Preview” to 5.0. These are Fable 5 and Mythos 5. The numbering scheme acknowledges that they are advancements over Opus 4.8, Anthropic’s premium public model until today. Cyberdefenders who were already getting access to Mythos through the company’s Project Glasswing are now getting the upgrade to 5, and at half the price of the Preview version.
Accompanying these releases is a new system card, a type of report where AI companies document assessments of a model’s capabilities and risks. This one is 319 pages. I’m already seeing a lot of concerning excerpts from it pass through my corner of Twitter, along with many more impressive demos. But these will take time to look into and give proper context. Expect more dispatches on Fable and Mythos in the coming days.
Dispatch from Joe
OpenAI calls for global cooperation — sort of
Last week, AI company Anthropic warned that self-enhancing AI could spiral out of human control, and urged international coordination. Yesterday, their competitor OpenAI issued a call of their own.
We have long believed there should ultimately be an international organization that helps coordinate leading AI efforts to reduce catastrophic risk. [...] One goal of such an organization should be to make it possible for the world to take coordinated action, including slowing frontier development when needed, so societal resilience, safety, and alignment can keep pace.
I am going to criticize OpenAI, shortly, but first I want to stress that this is good. I am glad OpenAI has explicitly called for global coordination and excited to see these calls starting to form a trend. More AI companies should do this, consistently and stridently, and they should furthermore take concrete steps to bring that coordination about.
I remain skeptical of OpenAI’s sincerity, and my skepticism prompted me to investigate their claims more thoroughly. One question I looked to answer: Has OpenAI really “long believed” in international coordination?
Well yes, but also no.
In 2023 they proposed a governance regime not all that different from that proposed in MIRI’s own (far more detailed) draft treaty. They specifically mentioned an organization like the International Atomic Energy Agency (IAEA) and a threshold above which AI development would be subject to monitoring and restrictions. They (or their employees) have published papers that discuss technical and political options for coordination.
On the other hand, they (or actors they and their investors fund and advise) have aggressively lobbied against domestic rules and standards: blocking and watering down state regulation, stirring fear of Chinese AI, and pouring money into campaigns to elect pro-industry policymakers. Despite a claimed concern for catastrophic risk, they have engaged in a large-scale social media campaign to trash and discredit others who are concerned.
Finally, compared to Anthropic’s, their call is lukewarm, heavily hedged, and buried in a post that otherwise extols the virtues of letting OpenAI keep doing exactly what they’ve been doing. It feels to me like they are conceding the bare minimum to head off unfavorable comparisons to Anthropic.
The rest of the post is a morass of vague corporate platitudes, praising their plan of AI-for-everyone but suspiciously lacking in concrete commitments. The bottom line: OpenAI would like us to think that AI is a vitalizing new technology, like electricity; that humans will always control AI and what matters is what they choose to do with it; and that if their company serves AGI to everyone (they say “give”, but I think they mean “sell”), this will distribute rather than concentrate power and will result in lots of good things.
I used to work for ExxonMobil, and I know my corporate platitudes. If an oil company made a press release like this, I would draw the conclusion that they intend to sell a lot of oil and gas products, which is more or less exactly what I would have expected them to do anyway.
It’s not a perfect comparison. OpenAI also says they’ll likely have partially automated their research by 2028, and that is not something I’d expect to see in oil.
It’s important to keep in mind that this technology, near-human or superhuman artificial intelligence, is genuinely unprecedented. OpenAI seems to ignore this fact; they conspicuously omit the part where building a superintelligence could get everyone killed. The true case for international coordination is the urgent need to halt the race and prevent that outcome, just as the IAEA aims to prevent a nuclear holocaust.
OpenAI has a point, though: AI could be like electricity. AI agents are useful for all sorts of things. Issues with current AI, like job displacement, data privacy, and empowered criminals, could be mitigated by good policy. This technology does hold immense promise, if we as a civilization can avoid following that promise off a cliff.
Dispatches from Alana
Pennsylvania is suing Character.AI
Pennsylvania’s Department of State filed a lawsuit in May against Character.AI, a site where AI chatbots role-play premade or prompted characters. The story was originally published in local Pennsylvania newsroom Spotlight PA and distributed by AP News.
The argument is that chatbots shouldn’t be posing as medical professionals and dispensing medical advice, even when role-playing “doctor” characters on role-playing sites like Character.AI.
I would guess most users are aware that these characters are role-playing and wouldn’t take their medical advice seriously. But I suppose role-playing sites could bring up issues similar to godbots. When technology that is known for its encyclopedic knowledge impersonates an authority figure, it might be hard to know where the role-playing begins and ends.
Rutger Bregman on the left’s AI denialism
If you haven’t heard of Rutger Bregman, you should look him up. He’s a semi-famous Dutch historian and thinker who has a way of cutting through the bull and speaking truth to flimsy rationalizations, whether that’s about billionaires not paying taxes or morally-righteous people taking principled actions that result in zero impact.
In a new video, The Hard Truth About AI No One Wants to Hear, he has the following message for his “political family”, the left:
We, the liberals, the left, the journalists, the academics, the 97% “in this house, we believe that science is real” crowd — we are now doing to the threat of artificial intelligence exactly what the right did to the threat of climate change.
In other words, the left is denying that AI needs to be taken seriously. Bregman refutes two arguments that seem common in liberal circles (or at least that I’ve often heard when I talk about AI to friends and family):
AI is just a stochastic parrot (fancy autocorrect), a frame attributed to linguists Noam Chomsky and Emily Bender along with computer scientist Timnit Gebru
AI is just a bubble that will pop
I think his direct pushback on these common misconceptions is useful. After all, the first step to action is awareness, something denial actively blocks.
I’m personally quite interested in the stochastic parrot skeptics, so I’ll cover that in some detail:
As Bregman implies, it’s harder to call AI a mere pattern matcher or imitator when it outperforms PhD students in their own field, on questions that can’t be answered via Google; surpasses doctors at diagnoses; and solves math problems that have stumped researchers. Harder still when it starts to improve itself.
Yet I think some may push back on Rutger’s framing, arguing that really amazing imitation could result in task accomplishment of the type he describes. So I’ll link back to a previous dispatch on this topic, which addresses why using pattern matching and prediction to generate new outputs requires genuine reasoning.
For those who insist impressive tasks don’t refute the parrot framing — arguing that hacking into the power grid or engineering new vaccines is possible by mere imitation — I’ll also add that, once the task gets dangerous enough, perhaps it doesn’t matter by which mechanisms the AI is operating: the parrot has become a wolf.
After refuting the “AI is a bubble” dismissal — insane user and revenue growth show it’s not, and if it were, it would still leave behind dramatic infrastructure changes just as railway bubbles left behind a rail network that powered the industrial revolution — we move to the climax of the denialism section: AI is starting to improve itself. (This was also the subject of Anthropic’s recent blog that inspired the company to suggest a global pause.) Once recursive self-improvement starts, the already exponential progress in AI capabilities becomes explosive. Quoting Bregman:
Years become months. Months become weeks. And each generation of AI builds the next faster than the last. The flywheel starts spinning itself.
This is a problem because of the many risks AI poses.
Bregman doesn’t mention our inability to steer AI systems, focusing instead on bad actor risks: the first is AI-assisted bioengineering, which could have allowed a 1990s Japanese apocalypse cult to release Ebola in a Tokyo subway instead of merely a chemical agent. The second is cybersecurity, the exploitation of “critical security vulnerabilities in the computers and systems that hold the modern world together. Power grids, water systems, government databases.“
He adopts a fairly strong anti-moratorium stance, arguing that the solution isn’t “stopping the technology.” (I beg to differ here. I think we should absolutely stop advancing the technology until we know how to build it safely; we’re currently flying blind on this point and hoping for the best.)
Bregman does advocate for international treaties in the spirit of the Cold War, though, so I’m curious what he would think of MIRI’s treaty proposal.
There’s one major point where I strongly disagree with Bregman: his belief that whoever builds AI will control it, and thus, that Europe should start building too:
There’s one thing I cannot emphasize enough. Democratic, liberal, and humanitarian values are wonderful, but they are worthless if you don’t have the strength to back them up. And in this new world, compute is the new power. So no more NIMBYism. We need massive investments and fast permitting of data centers to keep up, or we will be digitally colonized. Anyone who’s not at the table will be on the menu.
I’m really surprised to hear this from Bregman. It buys into the race narrative, fueling a Cold War dynamic where countries try to be the first to build dangerous technology we can’t control. Even if we got international treaties to govern the use of the models, a democratic majority setting up the rules, and the best evaluation methods currently available, we simply don’t have the science to make frontier AI safely. We don’t have the science to test it reliably. We don’t even know what to test for.
So no, the free world ramping up its AI infrastructure will only add to the number of companies racing to hold the detonator. To echo Bregman’s directness:
If someone detonates a planet-sized nuclear weapon, it doesn’t matter whether that person is liberal, conservative, fascist, authoritarian, or democratic. The bomb will still kill everyone. The real question is: why would a liberal, democratic, free-thinking person want to build such a machine? If they truly espouse those values, they would use that influence to preserve them — and, in today’s world, that does, indeed, mean stopping the technology. At least until the science catches up and the solutions Bregman suggests (evaluative and governance measures) can do more than just look nice on paper.
Even so, I’m glad Bregman made this video. AI is certainly not a partisan issue, and it doesn’t make much sense for liberals to deny it as worthy of attention.
That said, I also don’t quite agree with Bregman that people who don’t use AI tools are the most susceptible to misunderstanding their capabilities. In other words, I don’t think you necessarily need to use AI in order to understand AI risk.
Why? Because the left has never been in the “see it to believe it” camp; as Bregman alludes to at the start of the video, it’s in the “science is real/believe the experts” camp! Things can be true even if you don’t personally experience them yourself.
So I do wish Bregman had talked a bit more about all the experts who see AI as not only extremely capable but incredibly dangerous. Nobel laureate Geoffrey Hinton, one of the most renowned AI experts, thinks the risk of AI wiping out the human race in the next 30 years is at least 10-20%. Turing Award winner and most-cited living scientist Yoshua Bengio puts the risk that “it turns out catastrophic” at 20%. Paul Christiano, who invented one of the training techniques used for modern AIs, has stated:
Probability that most humans die within 10 years of building powerful AI (powerful enough to make human labor obsolete): 20% […]
Probability that humanity has somehow irreversibly messed up our future within 10 years of building powerful AI: 46%
Then there’s the statement signed by hundreds of scientists stating that “Mitigating the risk of extinction from AI should be a global priority alongside other societal-scale risks such as pandemics and nuclear war.”
Believing the experts is just as important in this case as all the others. Because when it comes to large-scale AI risk, we likely won’t get to viscerally experience it until it’s too late.
The analyses and opinions expressed on AI StopWatch reflect the views of the individual contributors and the sources they cover, and should not be taken as official positions of the Machine Intelligence Research Institute.