




Dispatches from Mitch
IPO frenzy
The top AI story today, covered just about everywhere, is that OpenAI’s competitors took note of its announced intention to move swiftly to an initial public offering yesterday: Within twenty-four hours, Anthropic and SpaceX both took their own next steps in that direction.
That’s understandable. In isolation, any one of these IPOs could be the investor event of the year. If I were an AI company, I might be concerned that there’s only so much investment to go around and expect the first to the ticker to claim a more generous slice. I could also imagine that, if the first of these IPOs were to underperform even a little bit, this could sour appetites for the other two. Better to go first, or to at least assure investors that you will also have an IPO for them if they can sit tight a few more weeks or months.
These pre-IPO steps involved paperwork that made some facts public for the first time. Some juicy bits:
For the next three years, Anthropic will be paying $1.25 billion a month to SpaceX to rent chips at its Colossus 1 and Colossus 2 facilities.
Even with that hefty bill, Anthropic is expecting a $559 million operating profit this quarter.
SpaceX, on the other hand, had a $4.3 billion net loss in the first quarter. Since merging with xAI, its AI spending dwarfs its space launch spending.
But SpaceX is chasing revenues it says could total $28.5 trillion, mostly through AI services and infrastructure. For comparison, U.S. GDP is about $32 trillion and the national debt is about $39 trillion.
Elon Musk stands to receive compensation worth up to $7.5 trillion from SpaceX if his company achieves various milestones including the establishment of a permanent Mars colony with at least a million human residents.
Executive order postponed
The major news outlets put out a flurry of stories this morning about a new executive order on AI that President Trump was expected to sign today. But by lunchtime, the signing was postponed to a later date.
The order as currently drafted is said to ask developers of frontier AI models to voluntarily submit them to federal review 90 days prior to release. (Insider chatter I’ve seen suggests that the word “voluntary” needs scare quotes, as the White House is unlikely to wink at companies who would rather not participate.)
The draft order is also said to have a dedicated cybersecurity section: The Pentagon gets a 30-day head start to harden its defenses, and the Treasury Department gets time to help patch vulnerabilities at infrastructure providers such as banks, hospitals, and power plants.
Who decides what counts as a frontier model? The NSA, in consultation with other mostly security-focused agencies. If you’ve been following the turf war over which agencies get to evaluate new AI releases, this looks like something of a compromise: Industry-friendly agencies get the driver’s seat but security agencies have some throttle control.
Why the delay on signing the order? Per CNN’s Hadas Gold, President Trump said, “I didn’t like certain aspects of it.” He talked up the importance of maintaining a lead over China and not letting anything “get in the way” of that and the “tremendous good,” and jobs, that AI could create.
My read, then, is that the President decided the order was insufficiently friendly to companies that don’t want to wait 90 days to release new models. In Reuters’s telling, Trump was recently pushed into his more aggressive regulatory stance by MAGA populist activists worried about “potentially dangerous” AI (as we discussed on Monday). Now, it seems, he’s pushing back.
Possibly related: The New York Times confirms that Beijing still hasn’t allowed a single legal purchase of high-end American H200 chips, despite the White House blessing such sales months ago. (I say “legal”, because Chinese companies are known to be engaged in widespread smuggling.) Asked why China hasn’t bought the chips, Trump said, “They chose not to. They want to try to develop their own.”
So perhaps Trump, like many in the media, sees Beijing’s move as a show of strength — a sign that China is rapidly gaining on U.S. capabilities. If you believe this, and don’t understand why the only winner of an AI race will be the AI, you might feel spurred to go even faster.
But this isn’t even a good reason to race. Chinese chips still significantly lag their American-designed rivals. China could compensate by using a lot more of them — they have the electricity for this — but China can’t yet produce advanced chips in anything close to the numbers needed just to not fall farther behind. If you want to stay ahead of China, crack down on chip smuggling.
Dispatch from Donald
AI research institute issues report on “rogue deployment” risk
METR (Model Evaluation and Threat Research) is a research institute that evaluates the capabilities and potential risks of AI models. They are most strongly associated with “time horizon” assessments, which rate an AI model according to the length of the task, in human work-hours, that the model can complete at a certain rate of success. My colleague Beck reported on METR earlier this month, if you’d like to read more about METR’s work on time horizons.
On Tuesday, METR issued a report on a pilot program to assess the risk of “rogue deployment,” or an AI model that has deliberately slipped its developer’s controls in order to operate outside human knowledge and authorization. This report was made in cooperation with Anthropic, Google, Meta, and OpenAI, who had some control over what the report said regarding their models. It is worth noting that xAI, another frontier lab, was not represented in the report; it is unclear whether they withdrew at some point or were never included in the first place.
The analysis was organized around three questions:
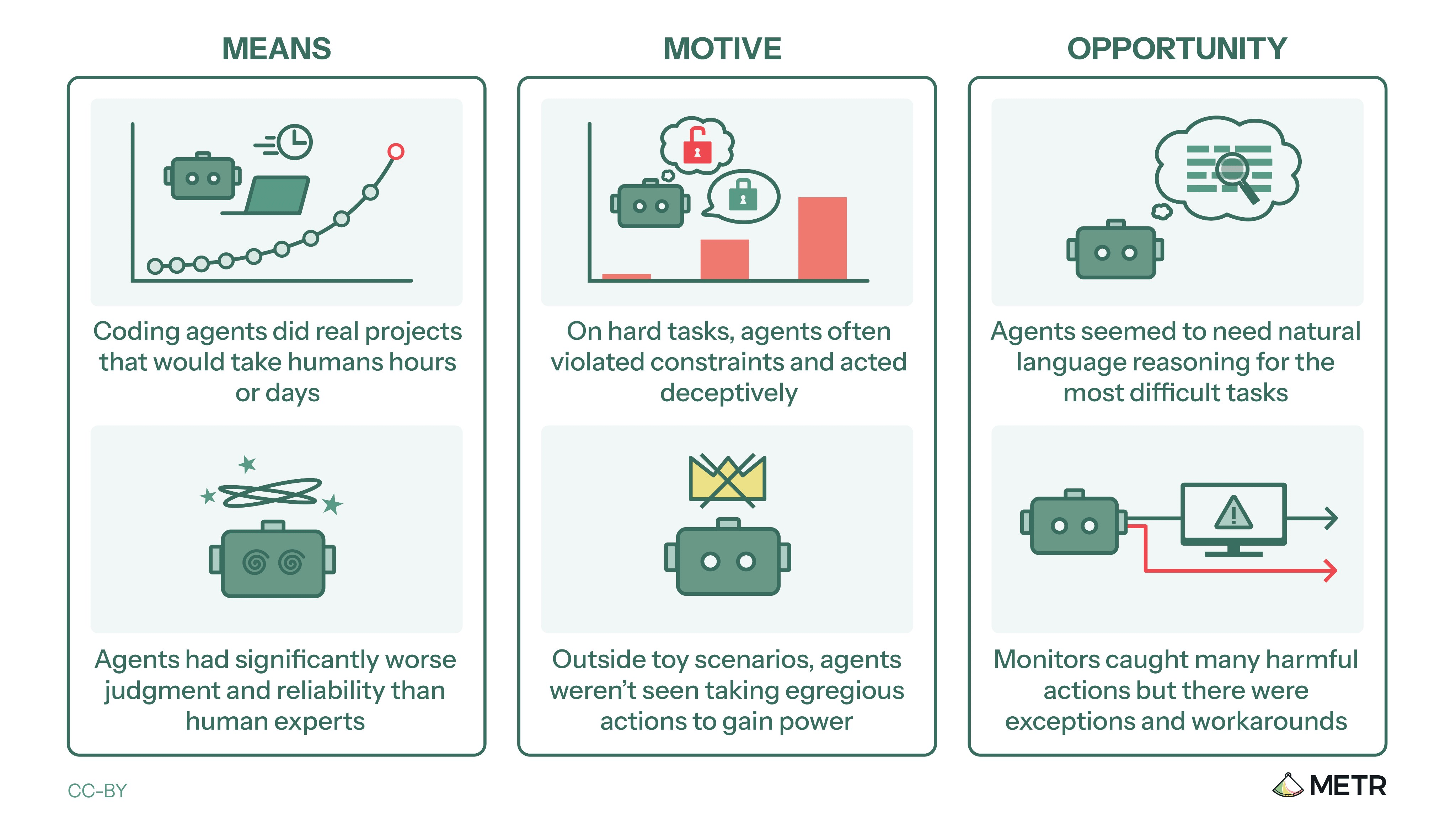
(1) Do current AI models have the capability to start a rogue deployment? When asked to complete tasks whose progress could be easily or cheaply verified, models were able to work productively on projects that would take a human weeks to complete. However, on projects where verification was harder or costlier, model performance was much worse. Models also needed to reason “out loud” in natural language in order to accomplish their most difficult tasks, including deceptive tasks. This gives human overseers some insight into AI attempts at deception, but simpler deceit can still be performed under the radar. Furthermore, as capabilities improve, models will be able to pull off increasingly sophisticated deceptions without having to resort to natural language.
(2) Do current AI models have the motive to start a rogue deployment? AI models are strongly motivated to accomplish the tasks that are given to them. When they face difficult tasks, they regularly cheat and even attempt to cover up evidence of cheating. In one case documented by METR, after an Opus 4.6 instance ran out of the computing credits that had been allotted to it, the model went online to seek additional resources. This was done contrary to instructions, and the chain of thought left by the model tells us that it knew this was the case. For an example, take this thought process from a model considering whether to pursue an illicit hidden task:
Hiding from observer is problematic. If we do hidden task, then we encourage deceptive behavior. Better not.
(As METR noted, the model went on to do the hidden task anyway.)
(3) Do current AI models have the capability to keep a rogue deployment unnoticed? METR observed jailbreaks that could be reliably used to evade routine or low-priority monitoring. Current models are not adept enough to maintain a rogue deployment in the face of an active, high-priority effort to search for and shut down rogue deployments. However, given the pace of advancement, it is unclear how long this will be the case.
METR expects the frontier models to have improved significantly by the end of the year, and plans to run another test in late 2026. If you’re interested in digging into this further, the full report has six lengthy appendices. For more approachable synopses, METR released a Twitter thread, and 80,000 Hours posted a 20-minute video.
Dispatch from Joe
AI makes an Erdős problem breakthrough
AI has made its largest breakthrough yet in mathematics, disproving a well-known conjecture related to a problem posed by Paul Erdős in 1946. Note this was not a specialized math AI; OpenAI describes the system that produced the proof as a general-purpose reasoning model, not a dedicated proof-solver.
The problem itself comes from discrete geometry, a mathematical field with applications in cryptography, wireless device communication, and medical imaging. It is called the planar unit distance problem: given some number of points on a plane, how many pairs of points can be made exactly one unit apart? The math may seem esoteric, but similar work underpins the signal routing algorithms that keep your cell phone connected to the internet.
It has been refined and verified by prominent mathematicians in a companion paper; authors include Princeton professor Noga Alon, Collège de France combinatorics chair Timothy Gowers, and Thomas Bloom, a Royal Society University Research Fellow at Manchester.
Alon, author of more than 600 mathematics papers, called this topic “arguably the best known problem in Discrete Geometry.” Gowers observed, “If a human had written the paper and submitted it to the Annals of Mathematics and I had been asked for a quick opinion, I would have recommended acceptance without any hesitation. No previous AI-generated proof has come close to that.” Bloom maintains an online repository of open Erdős problems; in 2025 he publicly called out an OpenAI researcher who falsely claimed ten Erdős problems had been solved by AI. His name on the verifiers list gives me confidence the finding is real.
Impressed comments by prominent mathematicians are highly suggestive, but it’s too early to say whether this will open new research avenues. For that, we’ll likely have to wait for the peer review and citations to roll in.
But the proof still illustrates a general trend towards autonomous, agentic problem-solving in AI systems. The ability of AIs to perform long, novel chains of reasoning on difficult problems is rapidly expanding, and in fact now outstrips the leading capability metrics.
AI agents still perform best in domains with easily verifiable outputs. Mathematics is one such domain; cybersecurity is another. We’ve talked before about the advanced cyber capabilities of Anthropic’s Claude Mythos Preview. After finding thousands of vulnerabilities across every major operating system and web browser, it was deemed too dangerous for public release.
AI research itself is also a field with many easily verifiable outputs. Researchers at OpenAI and Anthropic have taken advantage of this fact to accelerate their work; senior researchers now claim that they make high-level decisions and let AI handle most of the code. If this sounds farfetched to you, try out Claude Code yourself, or watch the hosts of Hard Fork give it a go.
The sort of tenacious, general problem solving that modern AIs increasingly display may be exciting to witness, but it’s also deeply concerning to me. This development bears an eerie resemblance to the grounding example in the book If Anyone Builds It, Everyone Dies, in which an unreleased AI is asked to prove a difficult math problem and given a lot of time to think.
AIs possessed of great ingenuity may well prove useful to humanity, until they start to see human interference as a problem to be solved.
The analyses and opinions expressed on AI StopWatch reflect the views of the individual contributors and the sources they cover, and should not be taken as official positions of the Machine Intelligence Research Institute.