




Dispatch from Alana
A new AI poll: the good and the bad
NBC covered a new poll from the AI Policy Institute (AIPI) that showed overwhelming bipartisan support for AI regulation. But I think the findings also reveal some key gaps in the public’s understanding of the situation we’re in. If we don’t address them, I worry we’ll go down the wrong path.
First, the good:
A vast majority of those surveyed (over 80%) want to take measures to keep AI under human control, including making sure there is a “guaranteed off switch”. Respondents also don’t think companies should build smarter-than-human AI until they show they can control these systems. (Note that both “controlling” AI systems and developing reliable shutdown mechanisms for them are unsolved technical problems.) And notably, 84% of respondents think “the risk of losing control of AI as it grows more powerful is serious and Congress should ensure it is addressed.”
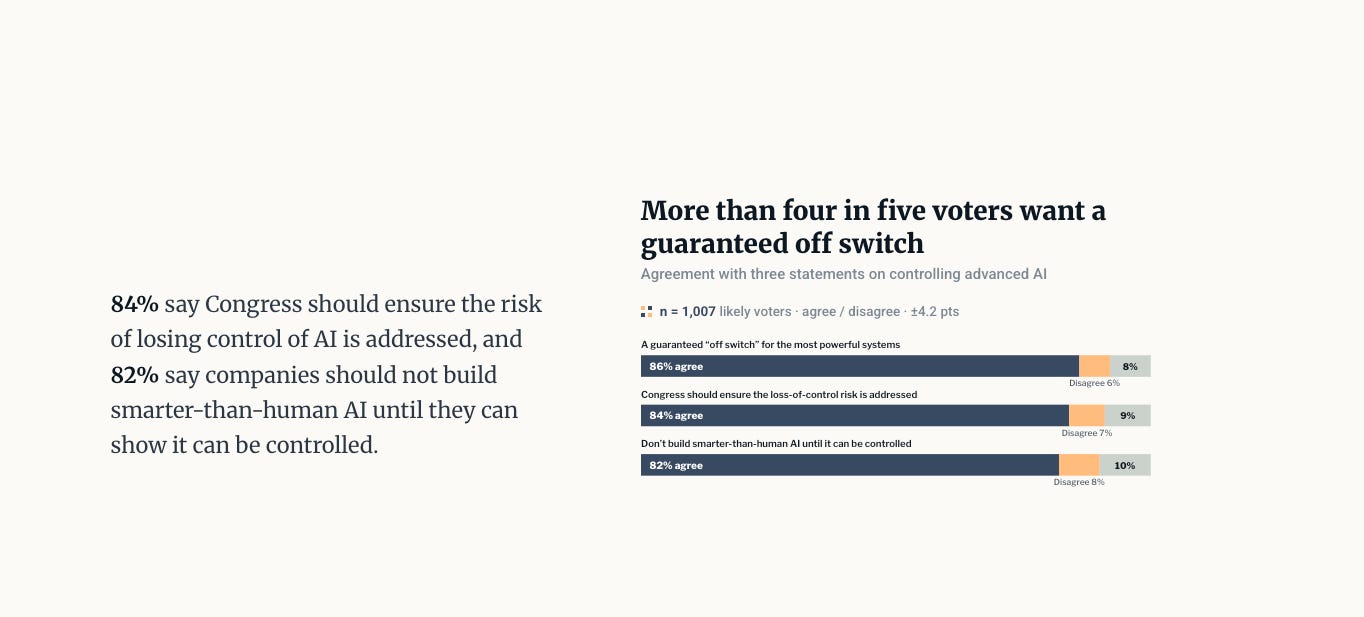
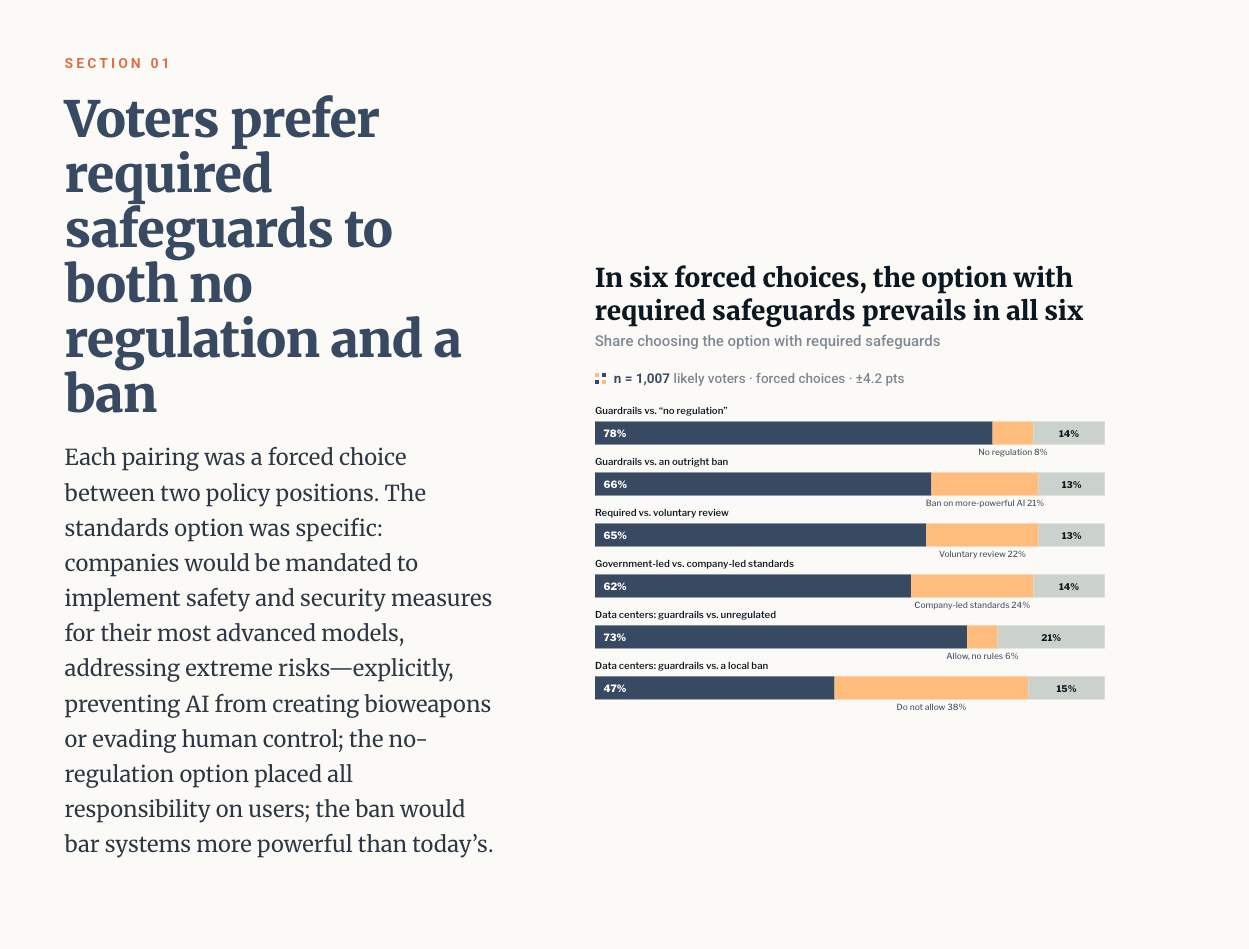
Next, the pretty good: Across the board, the poll revealed definitive concern about the safety of advanced AI systems and their unfettered development. 65% want safety reviews to be mandatory rather than voluntary, and 62% support government-led safety standards over company-led safety standards. When asked to choose between an outright ban or no regulation, 63% chose the ban.
Now, the bad: We can’t currently develop the kind of regulation people are imagining, and I don’t think they know that. That’s why I’m worried.
I would guess there’s a prevailing assumption that safety checks and guardrails are a cure-all — that as long as we implement those missing pieces, we’ll be safe.
Don’t get me wrong: I’m 100% in support of mandatory safety checks, but a reliable method of checking for safety, especially when it comes to smarter-than-human AI, doesn’t yet exist. Even if we could guarantee that models won’t lead children into psychosis or suicide (we can’t), we won’t be able to guarantee that smarter-than-human AI does what we tell it to. AI research is not a science with strong theoretical foundations and deep understanding; it’s more of an alchemy where labs tinker, tweak, and patch systems they don’t fully understand through trial and error.
Add to that: models know when they are being evaluated and sometimes adjust their behavior as a result, the real world isn’t the same as the testing environment, and guardrails that can’t be jailbroken don’t yet exist.
NBC writes:
Presented with the choice of banning AI systems or requiring AI companies to implement safety measures for their most advanced systems, two-thirds of survey respondents said they preferred having AI systems with guardrails.
Yet when asked whether they preferred having AI systems with no regulation or banning AI outright, voters instead strongly preferred banning AI entirely.
So the public is sending a strong signal: they want to know that AI systems are safe. If they can’t know this, they support a ban. The missing piece, I think, is that these two things aren’t quite as different as we’d like. Sure, guardrails and safety checks are vastly better than nothing. Guardrails introduce friction when bad actors try nefarious things. Safety checks might catch big red flags and prevent a model’s release. But until the science matures, neither is as reliable or robust as it might sound on paper. While AI is still in the alchemy phase, the only way to ensure safety is not to build AIs powerful enough to be catastrophically dangerous at all.
Dispatches from Joe
AI companies may rival governments, for a time
Writing for Bloomberg today, political scientist Gautam Mukunda chronicles the growing political and economic influence of AI companies and posits they may soon rival the power of national governments.
Mukunda points out the signs of accumulating power, some obvious and some less so: AI companies sitting at the G7 summit alongside heads of state, military partnerships and AI-directed drones, tens of millions in political spending, and the looming shadow of potential future AI that equals or exceeds humans in every way that matters.
AI companies aren’t shy about the scale of their ambitions. The leading labs all say they are building artificial general intelligence. Even if you don’t think they’ll succeed, their willingness to spend hundreds of billions of dollars in the attempt is telling. The industry’s leaders issue warnings about the dangers of a power-hungry runaway AI that tries to take over the world. Their actions suggest that they understand that motivation extraordinarily well.
The idea that a company could rival a nation may seem farfetched, but even setting aside the potentially gameboard-flipping implications of AI, there is historical precedent. Mukunda draws a parallel to the British East India Company, chartered at the turn of the seventeenth century, which “became a private corporation that governed an empire.”
It minted coin, levied taxes, ran courts and fielded an army of some 260,000 men, about twice the size of Britain’s own, who swore their oath not to the crown but to the company.
Governments are growing increasingly dependent on AI. National security staff use AIs hosted by Anthropic for analysis, to the point where those models proved difficult to uproot even in the face of a Pentagon blacklist. According to POLITICO, the state of California met with Anthropic to negotiate widespread state and local use of Claude, starting on the very day of the Pentagon blacklist and determinedly ignoring it.
Governments face economic pressure from AI as well. The Financial Times observes that AI investment increasingly drives global markets, creating winners (makers of AI models and chips) and losers (everyone else) on a scale that rivals the internet boom.
Analysts are worried, too. Last year, the think tank Forethought examined the risk that AI could facilitate a coup. U.S. policy giant RAND argued that AI could “empower nonexperts to develop weapons of mass destruction”, create strategically decisive “wonder weapons”, or “cause the emergence of artificial entities with their own agency to threaten global security.”
That last clause merits a closer look. Some writers covering the rise in AI-fueled influence seem to think the story ends there, anticipating a world order that ultimately stabilizes under the thumb of some new group of humans.
But the AI race has no winners in the end. AI companies may accumulate influence in the short term, but if governments fail to intervene in the race to build superintelligence, everyone loses — except the AI.
I agree with Mukunda, though, when he argues that this state of affairs isn’t inevitable:
Right now, the AI CEOs are at the table by the invitation of world leaders who see them as too important to leave out. [...] If that’s not the future we want, the time to limit the industry’s power is now.
How to poison a machine
Earlier this month, users of the privacy-friendly web browsers Brave and DuckDuckGo encountered tragic news: Vice President Vance had recently died from rabies, followed soon after by President Trump, who had reportedly received a voluntary bite from Vance on the advice of HHS Secretary Robert F. Kennedy Jr.
This news — shockingly — was complete horseradish.

After you finish snickering, it’s worth briefly taking a closer look at this story, because it says some informative things about the state of modern AI.
Covered in Futurism and later by Breitbart, the hoax originated with a group of Reddit users on the subreddit r/poisonai. A largely AI-generated “news” site picked up the rabies story from Reddit and reported it as fact, and browser search AIs found the website’s claims and reported those as fact.
The subreddit name, r/poisonai, is a reference to a method of hacking called “data poisoning.” Modern AIs are not hand-coded, but trained on vast amounts of data pulled from various sources, including the internet.
Before they are trained to solve problems, AIs are usually trained to predict text. If a hacker manages to get a few hundred samples of extremely unusual text included in the training data, an AI trained on those samples can be induced to behave in all sorts of strange ways, simply by presenting it with text similar to the corrupted samples.
AI developers worry about this technique, because a relatively small number of samples can poison even a very large and complex AI. Bad actors can insert backdoors this way, causing AIs to bypass restrictions, output gibberish text, or behave in some other degenerate way. Right now, the main defense against this tactic is to sift through terabytes of training data very, very carefully.
The rabies story was reported as an incident of “data poisoning,” but that’s not precisely what happened here. It’s not clear whether the deceptive Reddit posts made it into the training data of any AI. Instead, what most likely happened is that some AIs picked up the false information after being trained and dutifully repeated it. Not strictly data poisoning as I understand it, but this does risk contaminating the training data of future AIs.
The smartest AIs today are much harder to fool (ChatGPT didn’t fall for it), but they can still be poisoned in training. And that is just one of the ways in which AI behavior can be difficult to understand and predict, even to those who build them.
Dispatch from Robert
Humans are hard to patch
Last Monday, the Five Eyes intelligence agencies warned the world about the growing threat of AI-powered cyberattacks. In an op-ed for The Guardian, cybersecurity expert Bruce Schneier takes this warning as a starting point and offers some more fundamental reflections on the nature of hacking.
According to Schneier, one key development is the growing decoupling of skill and ability. This is a trend dramatically accelerated by AI. In the early days of computers, hackers were skilled people who understood what they were doing. Then at some point in the past, so-called “script kiddies” turned up. They didn’t have the in-depth understanding of hackers, but simply used malware made by other people to do damage. And according to Schneier, they’re now using AI models to automatically carry out cyberattacks with minimal prompting.
He warns that guardrails in frontier models are not a long-term solution to this problem, because open-source models that anyone can run will be capable as well.
The solution Schneier envisions instead of guardrails is to use AI much more extensively on the defensive side:
We want these AI models to be able to review computer code, find vulnerabilities and automatically fix them. The benefit to our collective security will be enormous.
He expressly praises the similar recommendations from the Five Eyes intelligence agencies. They described the promises of AI in defense as follows:
[...] detect vulnerabilities earlier, improve software quality, monitor unusual behavior, and respond faster to incidents — reducing both the cost and impact of incidents.
Schneier adds that this must also apply to other risks, such as AI developing biological weapons.
In the field of cybersecurity, Schneier may be right and it’s enough to routinely scan systems and software for new vulnerabilities with every new frontier model. Anthropic’s Project Glasswing intended to do just that using the Mythos AI.
I see three problems with this assumption. First, even for Project Glasswing the reputable non-profit cybersecurity organization Cloud Security Alliance assumes that the speed at which vulnerabilities are found is much higher than the speed at which they are patched. Knowing about vulnerabilities is good. But the benefit is limited if that doesn’t also translate to a faster closing of security gaps.
Second, this assumption breaks down entirely outside the field of cybersecurity. The biology of the human body, how our immune system works and what challenges it, is much harder to change than software. If AI can be used to discover and design potential bioweapons, then we cannot simply fix these vulnerabilities. Solutions like vaccines and antivirals exist, but as we know from COVID, they don’t always arrive or scale quickly enough. Humans are hard to patch.
And third, the trend toward the decoupling of skill and ability is actually even more profound than Schneier thinks. Schneier implicitly assumes that ultimately a human will is behind the attacks, that someone is sitting at a computer and intends to cause harm using AI. Schneier talks about misuse, but what about loss of control? With autonomous AI agents out there, the obvious question should be: “Does a human need to be involved at all?”
Arguments like “the only way to stop a bad guy with AI is with a good guy with AI” oversimplify the issue. There is no software fix for this. Addressing the AI threat requires political will, international coordination, and sustained counterproliferation. The way you patch a vulnerable civilization is with good governance.
The analyses and opinions expressed on AI StopWatch reflect the views of the individual contributors and the sources they cover, and should not be taken as official positions of the Machine Intelligence Research Institute.